Мониторинг серверов: инструменты для контроля работы оборудования

Бесперебойная работа серверов невозможна без постоянного контроля. Мониторинг помогает вовремя выявлять сбои, прогнозировать нагрузки и повышать надежность инфраструктуры. Обзор ключевых инструментов для управления серверным парком.
В этой статье
- Зачем бизнесу мониторинг серверов
- Что именно можно отслеживать
- Виды мониторинга
- Как внедрить систему мониторинга
- Ошибки, которых следует избегать
- FAQ

За следующие пять минут вы узнаете, зачем бизнесу нужен мониторинг серверов, как выбрать подходящие инструменты и избежать ошибок, которые могут стоить миллионов рублей. Мы разберем ключевые метрики, типы систем и ответим на главные вопросы, чтобы вы могли внедрить решение уже завтра.
Зачем бизнесу мониторинг серверов

Компании зависят от цифровой инфраструктуры: отказ сервера на час может привести к потере клиентов или штрафам. Например, в 2022 году сбой в работе облачного провайдера вызвал простой у 5000 предприятий, а средние убытки составили $10 000 в час.
Мониторинг обеспечивает предупреждения об ошибках, позволяет предотвратить негативные сценарии, отслеживая работоспособность оборудования в режиме реального времени. Это не просто "техническая прихоть" - это страховка для репутации и финансов. Системы вроде Zabbix или Nagios фиксируют аномалии до того, как они приведут к сбою оборудования, а интеграция с мессенджерами, например, Slack ускоряет реакцию команды.

Что именно можно отслеживать
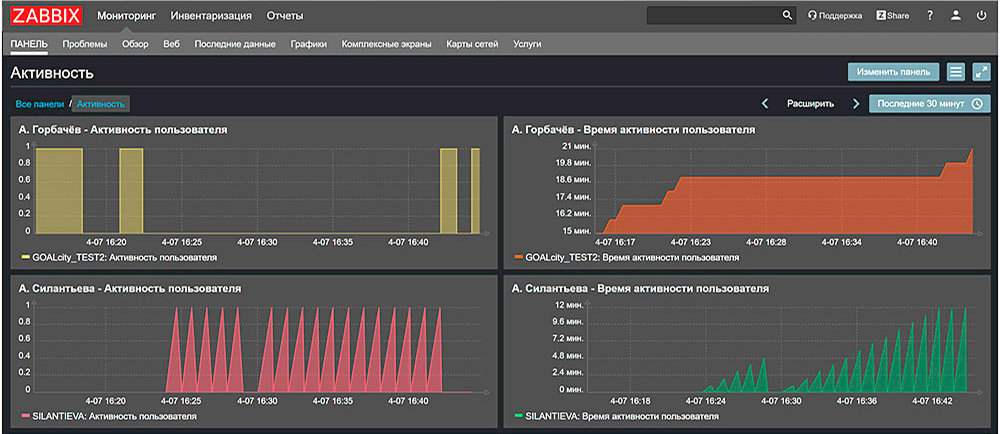
При наблюдении за работой серверного оборудования контролируют:
-
загрузку процессора, разрешается нагрузка до 70%;
-
температуру компонентов. Перегрев HDD выше 45 °C сокращает срок службы на 30%;
-
дисковое пространство. Заполнение на 90% HDD замедляет операции в 2-3 раза;
-
сеть. Сетевые задержки свыше 100 мс для веб-сервисов приводят к оттоку пользователей. Например, каждая лишняя миллисекунда задержки увеличивает отток пользователей на 1%.
Отслеживание логов помогает выявлять паттерны атак: например, 10 неудачных попыток входа за минуту могут сигнализировать о брутфорсе.
Виды мониторинга
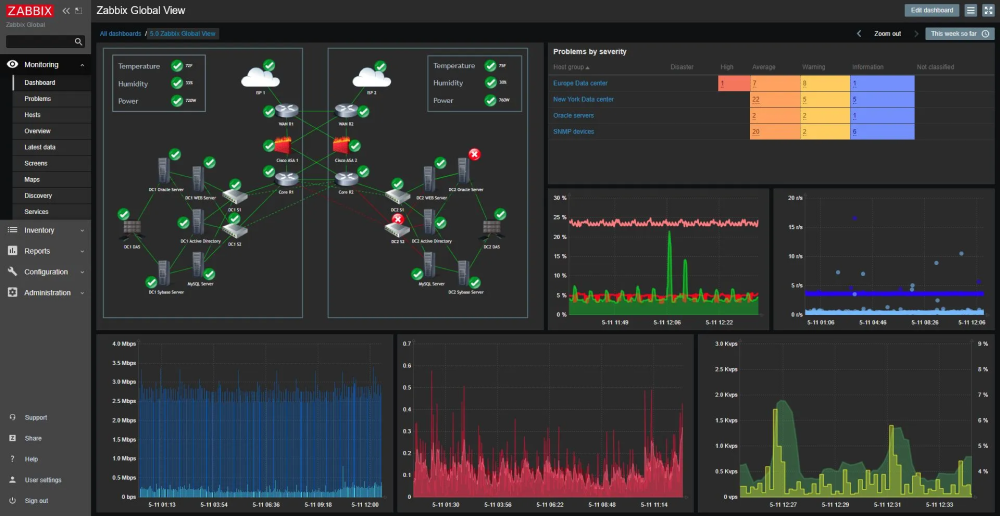
Существует три подхода:
-
Активный. Активный (например, Pingdom) имитирует действия пользователей, проверяя доступность сервисов.
-
Пассивный. Пассивный (Wireshark) анализирует реальный трафик, но требует больше ресурсов.
-
Гибридный. Гибридные системы, как PRTG, сочетают оба метода, снижая риск ложных срабатываний.
Для облачных решений (AWS CloudWatch) характерна автоматическая адаптация под нагрузку, а локальные инструменты (SolarWinds) дают полный контроль над данными, но требуют ручной настройки.
Как внедрить систему мониторинга
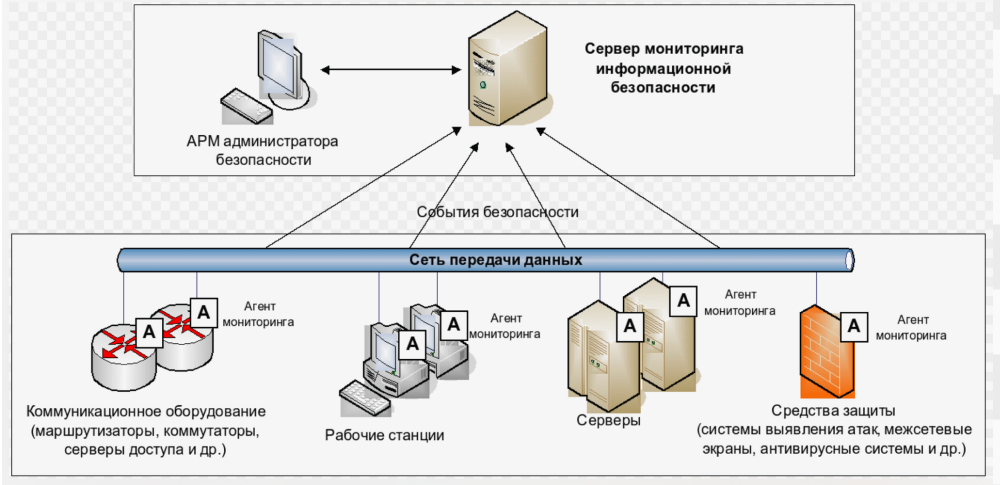
Начните с аудита: определите, какие серверы в скором времени дадут сбой, составьте карту зависимостей. Например, отказ базы данных остановит CRM, но не повлияет на архив.
Выберите метрики - для почтового сервера важна пропускная способность, для файлового хранилища - скорость чтения/записи.
Настройте пороги уведомлений: если нагрузка на ЦП превышает 80% дольше 5 минут, необходимо проверить работу комплектующих устройства. Тестовый запуск выявит слабые места.
Внедряйте систему мониторинга постепенно: сначала пилотная группа серверов, затем масштабирование. Интеграция с ITSM-системами (Jira, ServiceNow) автоматизирует создание инцидентов.
Ошибки, которых следует избегать
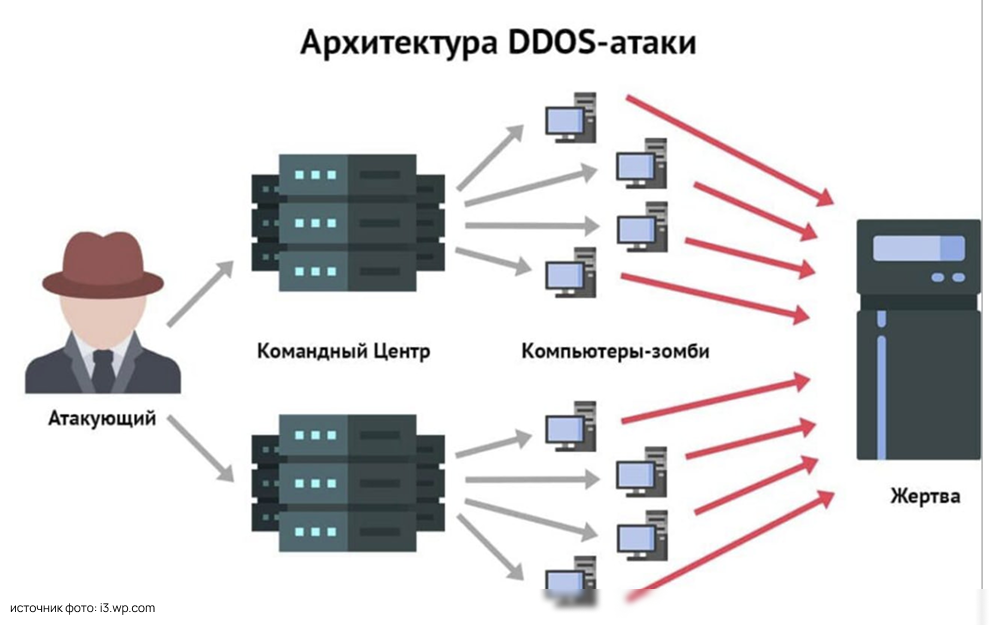
Один из основных промахов молодых системных администраторов - сбор множества данных, которые не несут полезной информации. Например, дублирование сенсоров: сбор данных о температуре CPU виртуальной машины через гипервизор VMware vSphere при уже настроенном мониторинге физического хоста через IPMI. Это не только перегружает хранилища данных, влияя на производительность Elasticsearch-кластера, но и создаёт "шум" в аналитике. Решение - настройка исключений в агентах Telegraf, Zabbix Agent для фильтрации избыточных показателей.
Вторая ловушка - некорректная калибровка триггеров. Если система генерирует алерт при 5%-ной нагрузке на CPU длительностью 10 секунд без учёта контекста, вроде ночного бэкапа, то системный админ перестает обращать внимание на такие некритичные ошибки. Используйте инструменты вроде Prometheus с Victoria Metrics, позволяющие применять функции quantile() или predict_linear(), чтобы отличать аномалии от плановых пиков.
Недооценка резервирования каналов уведомлений тоже считается ошибкой. Если основной сервер SMTP недоступен, а Telegram-бот зависим от DNS, алерт умрёт в очереди RabbitMQ. Решение: мультипротокольные шлюзы, например, Alertmanager), отправляющие сообщения параллельно через Slack Webhook, MS Teams и GSM-модем. Тестируйте каналы ежеквартально - имитируйте сбой через Chaos Engineering и проверяйте доставку.
Мониторинг 1000 серверов с частотой опроса 10 секунд генерирует ~8 Гб трафика в час при размере пакета 2 Kb. Без QoS или выделенного VLAN это вызовет задержку между отправкой запроса и получением ответа в основном трафике. Ограничивайте частоту сэмплирования для некритичных метрик - например, проверки состояния LVM-томов раз в 5 минут будет достаточно.
И последнее: "немые" алерты. Если уведомление о перегреве GPU в render-ферме не содержит инструкций, например, "Перезапустите службу CUDA через systemctl restart nvidia-coolbits", сотрудник потратит время на диагностику. Используйте шаблоны в Grafana или Splunk с pre-approved решениями - это сократит MTTR на 30-40%.
FAQ
Что будет, если не использовать мониторинг?
Риски включают незамеченные сбои (например, медленная деградация диска), ведущие к внезапному отказу. В 40% случаев компании узнают о проблеме от клиентов, теряя доверие.
Какие метрики наиболее важны?
Для веб-серверов - время отклика и аптайм; для БД - количество активных соединений; для сетевого оборудования - потеря пакетов.
Можно ли объединить мониторинг сервера и СХД?
Да, инструменты вроде NetApp Active IQ позволяют отслеживать серверы и системы хранения в единой панели, коррелируя данные (например, влияние нагрузки СХД на скорость обработки запросов).
Как быстро реагировать на уведомления?
Автоматизируйте рутинные задачи: скрипты для перезагрузки служб или переноса нагрузки на резервные узлы. Для крупных серверных систем предусмотрите круглосуточный дежурный штат.
Какой инструмент проще внедрить?
Cloud-based решения типа Datadog не требуют установки - достаточно настроить агенты. Для локальных сетей подойдёт Zabbix с готовыми шаблонами.
Есть ли облачные решения?
Да, например, AWS CloudTrail или Google Stackdriver. Они масштабируются автоматически, но зависят от интернет-соединения.
Можно ли мониторить сервера удаленно?
Да, через VPN или агенты с TLS-шифрованием. Важно ограничить доступ по IP и использовать двухфакторную аутентификацию.
Как защитить систему мониторинга?
Выделенный VLAN, регулярное обновление ПО, аудит логов доступа. Инструменты вроде Splunk помогут отслеживать подозрительную активность.
Что дешевле - готовое решение или свое?
Для малого бизнеса выгоднее облачные сервисы. Крупные компании с более высокими требованиями к оборудованию могут разработать собственные системы интеграции физического сервера и облачного решения.






Подробнее...


Подробнее...






