Топ-10 причин падения серверов и как их избежать


Каждую минуту простоя компании теряют не только деньги, но и доверие клиентов. Мы в CRABBIT ежедневно видим, как, казалось бы, стабильная инфраструктура рассыпается за секунды. Исследования показывают, что в 2025 году количество глобальных сбоев выросло в 4 раза по сравнению с 2024-м, а 45% инцидентов связаны с проблемами электропитания и перегревом.
Но часто серверное оборудование ломается не из-за фатальной неизбежности, а из-за цепочки мелких ошибок, которые можно было предотвратить. В этой статье мы собрали 10 главных причин падения серверов и дали четкие инструкции, как их избежать, чтобы ваш бизнес работал без сбоев 24/7.
В этой статье:
- Перегрев: «Тихий убийца» железа
- Человеческий фактор и ошибки конфигурации
- DDoS-атаки и хакерские вмешательства
- Дешевое «железо» и экономия на надежности
- Проблемы с питанием и отсутствие ABP/ИБП
- Перегрузка и нехватка ресурсов
- Выход из строя жестких дисков (RAID-массивов)
- Отсутствие резервного копирования и плана восстановления
- Вредоносное ПО и скрытые вирусы
- Износ сетевого оборудования и кабельной системы
Перегрев: «Тихий убийца» железа

Даже самое надежное «железо» чувствительно к температуре. Если система охлаждения в серверной дает сбой или забита пылью, процессоры и жесткие диски начинают работать на пределе. Это приводит к микро-ошибкам, а затем и к аварийному отключению.
По нашим данным сервера падают именно в жаркое время года, когда кондиционеры не справляются с пиковой нагрузкой. Мы в CRABBIT сталкивались с кейсами, где причиной внезапной остановки был банально забитый вентилятор в блоке питания.
Давайте посмотрим, как избежать перегревов в жаркое время:
- Внедрите постоянный мониторинг температуры.
- Используйте специализированные стойки с правильной организацией холодных и горячих коридоров.
- Не экономьте на кондиционировании — для небольшой серверной подойдут прецизионные кондиционеры, а для ЦОД — полноценные системы климат-контроля.
- Профилактическая чистка оборудования от пыли раз в полгода — обязательна.
Следите за температурой в серверной. Перегрев не убивает устройство мгновенно, но гарантированно сокращает его жизнь и вызывает нестабильность.
Человеческий фактор и ошибки конфигурации

Почему оборудование ломается как будто само по себе, хотя железо и софт новые? «Сам по себе» — это практически всегда ошибка в настройках или конфигурации. Свежий пример — массовый сбой Cloudflare в ноябре 2025 года. Сервер упал не из-за хакеров, а из-за одного-единственного «раздутого» файла конфигурации, который нарушил работу сети по всему миру. Это может быть неправильно настроенный DNS, важные ошибки в правах доступа или некорректное обновление ПО.
Давайте посмотрим, как избежать этих проблем.
- Любые изменения в конфигурации проводите через тестовую среду.
- Используйте системы контроля версий для конфигов и внедряйте правило «четырех глаз» (один настроил, второй проверил).
- Всегда используйте откат до последней стабильной версии при появлении мелких проблем.
80% внезапных сбоев — результат действий человека или его бездействия. Автоматизация и контроль — ваши главные помощники.
DDoS-атаки и хакерские вмешательства
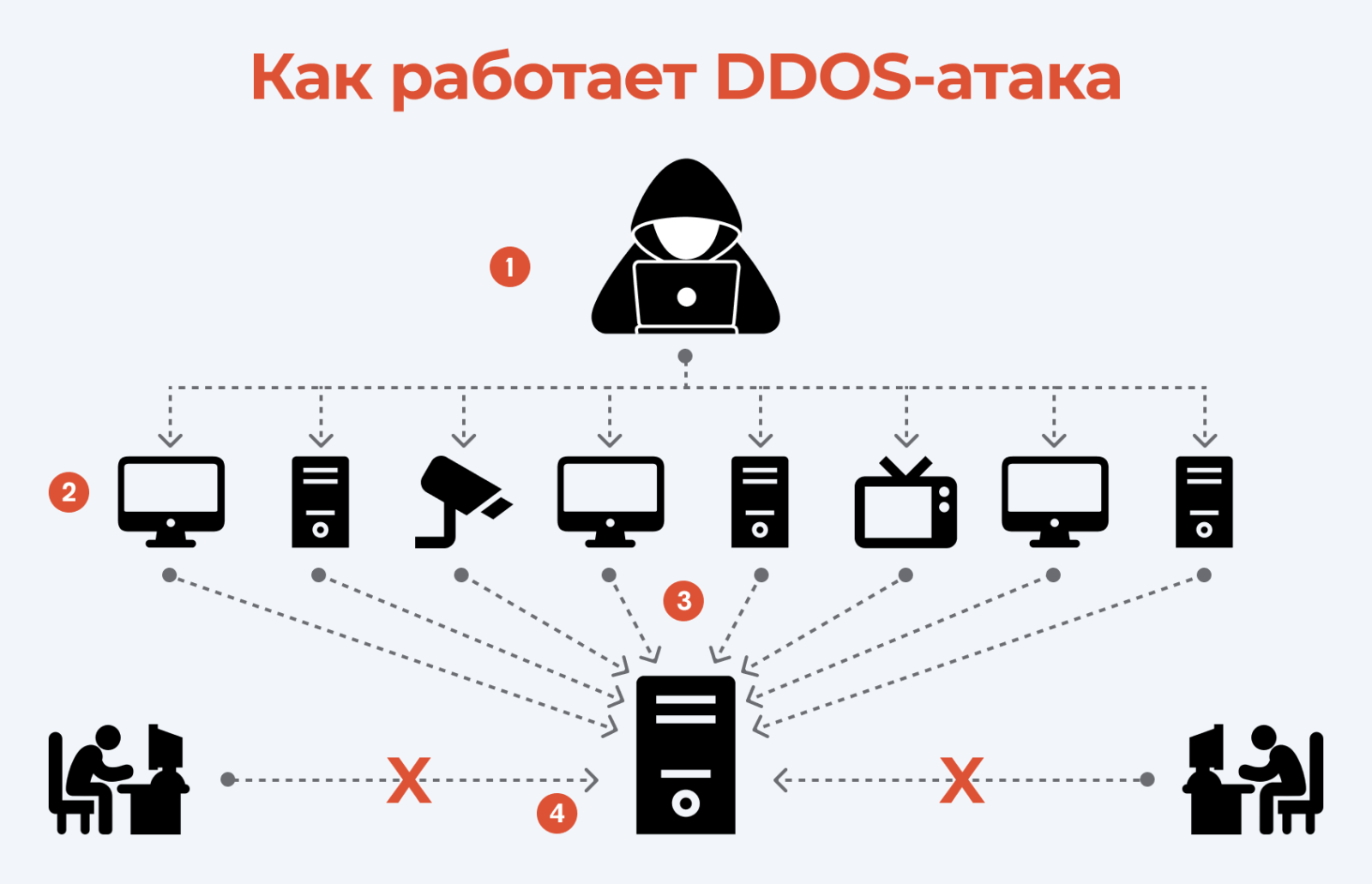
2025 год стал рекордным по числу и мощности DDoS-атак. Злоумышленники не просто ломают безопасность, они перегружают каналы связи и вычислительные мощности сервера лавиной бесполезных запросов. Упавший сервер в таком случае — это способ остановить торговлю, сорвать тендер или просто навредить конкурентам.
Чтобы защититься от DDoS атак и хакеров:
- Используйте профессиональные решения для фильтрации трафика — аппаратные или облачные WAF-файрволы и анти-DDoS сервисы.
- Убедитесь, что ваш провайдер или партнер, может предложить защиту на уровне канала и приложений. Например, наши специалисты могут дать вам многоуровневую защиту, а какую именно можно узнать, обратившись в наш консультационный отдел.
Готовьте инфраструктуру к отражению атак заранее.
Дешевое «железо» и экономия на надежности

В чем опасность сборки сервера на компонентах для ПК? Использование обычных комплектующих вместо серверных — это бомба замедленного действия. Серверные процессоры, память с коррекцией ошибок (ECC) и жесткие диски (HDD/SSD) рассчитаны на работу 24/7 под высокой нагрузкой. Обычный ПК может не выдержать даже года беспрерывной работы. Физический износ дешевых дисков — одна из частых причин, почему сервер ломается и не подает признаков жизни.
Поэтому собирайте серверы только из проверенного серверного оборудования. В CRABBIT мы помогаем подобрать конфигурации, которые будут работать годами. Обратите внимание на корпуса и блоки питания — они должны иметь резервные места и мощности для масштабирования бизнеса.
Внимание!Скупой платит дважды. Экономия на этапе сборки оборачивается миллионными убытками от простоев.
Проблемы с питанием и отсутствие ABP/ИБП

Почему внезапное отключение электричества убивает данные? Скачки напряжения или внезапное отключение света — главные враги электроники. Если в серверной нет качественного источника бесперебойного питания (ИБП) и системы автоматического ввода резерва (АВР), даже кратковременное моргание света приведет к жесткой перезагрузке. Это чревато не только потерей несохраненных данных, но и повреждением файловой системы жестких дисков.
Поэтому установите мощные ИБП с возможностью горячей замены батарей. Для важных узлов используйте дизель-генераторы. Проверяйте нагрузку на АВР — она не должна превышать 70–75% в пике. Помните, что без нормального электропитания любой разговор о стабильности — пустой звук.
Перегрузка и нехватка ресурсов

Почему сервер падает, когда приходит много клиентов? Рост бизнеса — это радость, но для сервера это стресс. Если вы запустили рекламную кампанию, и на сайт хлынул поток посетителей, а мощности сервера не были рассчитаны на такой всплеск, он просто упадет.
Используйте масштабируемое оборудование. Например, присмотритесь к облачным платформам или виртуализации. Эти инструменты позволяют добавлять ресурсы (процессор, память) на лету без остановки сервиса. Регулярно проводите нагрузочное тестирование.
Готовьте инфраструктуру к пикам заранее или используйте автоматическое масштабирование.
Выход из строя жестких дисков (RAID-массивов)

Что делать, если сервер не видит диски? Срок службы серверного HDD редко превышает 3-5 лет. Однако проблема не в самом отказе, а в его последствиях. Часто администраторы, полагаясь на RAID-массив (зеркалирование), забывают, что два диска в зеркале физически находятся в одном корпусе. Пожар, короткое замыкание или падение стойки уничтожают оба диска одновременно — данные пропадают безвозвратно.
Соблюдайте правило «3-2-1»: три копии данных, на двух разных носителях, одна из которых — вне серверной (в облаке или другом ЦОДе). Используйте «горячие» замены и регулярно проверяйте целостность массивов.
RAID — это не резервная копия, а лишь способ повысить доступность.
Отсутствие резервного копирования и плана восстановления

Упавший сервер возможно вернуть к жизни? Реальный кейс спасения бизнеса:
История одной торговой компании
При переезде грузчики уронили серверную стойку. Жесткие диски вышли из строя, а резервные копии хранились на том же упавшем сервере. Бизнес повис на волоске. Спасти ситуацию удалось только чудом – старой копией базы у подрядчика и экстренным развертыванием инфраструктуры в облаке. Упавший сервер без бэкапа — это почти всегда потеря бизнеса.
Настройте автоматическое резервное копирование во внешнее хранилище. Разработайте и регулярно тестируйте Disaster Recovery Plan (DRP). Ответьте себе на вопрос: «Если сервер сгорит сегодня, через сколько часов мы запустимся на новом?»
Пока у вас нет внешней резервной копии, ваши данные в опасности.
Вредоносное ПО и скрытые вирусы

Топ-1 причина сбоев: майнеры и шифровальщики. Самый «популярный» бич последних лет — скрытые майнеры криптовалют. Они загружают процессор на 100% в фоне, из-за чего сервер начинает дико тормозить и в итоге падает от перегрева или нехватки ресурсов для критических задач. Шифровальщики же просто блокируют доступ к данным, требуя выкуп.
Регулярно обновляйте ПО, используйте антивирусы с анализом поведения (HIPS), ограничивайте права пользователей и запускайте сканеры на поиск руткитов.
Вирусы сегодня работают тихо, но убивают надежность инфраструктуры так же эффективно, как и DDoS.
Износ сетевого оборудования и кабельной системы

Почему происходит потеря пакетов и разрыв соединения? Даже если сервер работает идеально, проблемы на линии могут создать иллюзию его падения. Перегревающиеся коммутаторы, поврежденная витая пара или некачественные коннекторы приводят к высокому пингу, потерям пакетов и обрывам соединения. Это особенно важно для игровых серверов и высоконагруженных систем реального времени.
Используйте качественные кабели и оборудование Enterprise-уровня. Проводите регулярный аудит сети, проверяйте уровни сигнала и заменяйте изношенные патч-корды.
Таблица: Чек-лист профилактики падений серверов
|
Причина |
Частота проверки |
Кто отвечает |
Инструменты решения от нашей компании CRABBIT |
|
Перегрев |
Еженедельно |
Инженер |
Мониторинг температуры, замена кулеров |
|
Ошибки конфигурации |
При каждом изменении |
Администратор |
Тестовые стенды, контроль версий |
|
DDoS-атаки |
Постоянно |
Специалист по безопасности |
Аппаратные файрволы, фильтрация трафика |
|
Износ HDD/SSD |
Ежемесячно (S.M.A.R.T.) |
Системный администратор |
Своевременная замена, использование RAID |
|
Резервное копирование |
Ежедневно |
DevOps |
Настройка бэкапов в облако CRABBIT |
Теперь вы знаете почему ваш сервер упал. Помните, что стабильность складывается из мелочей: правильного охлаждения, качественного питания, настроенного мониторинга и, самое главное, надежной резервной копии.
Мы в компании CRABBIT более 10 лет занимаемся тем, что не даем серверам упасть. Наш опыт и экспертиза помогают бизнесу клиентов работать без простоев.
Хотите проверить надежность своей инфраструктуры?
Закажите аудит серверного оборудования у наших специалистов или подберите готовое решение под ваш бизнес с помощью конфигуратора серверов. Не ждите, пока упавший сервер поставит крест на вашей прибыли — свяжитесь с нами сегодня для бесплатной консультации!






Подробнее...



Подробнее...



Подробнее...


